/Primary%20with%20tagline%20(300%20wide).webp?width=150&height=62&name=Primary%20with%20tagline%20(300%20wide).webp)
Safely managing highly sensitive configuration is a problem that must be solved for nearly every non-trivial application.
This article describes the architecture we implemented at Giftbit to store and access sensitive system configuration. Our approach ensures that the configuration is stored in an encrypted format while providing the application a secure method to access it.

Configurations such as third party API keys, database passwords and other sensitive system parameters are secrets that, if leaked, can have catastrophic repercussions. Although storing these secrets plays a critical role in application security, most implementations still fall short by failing to adhere to the principle of least-privilege. The principle of least-privilege states that a user or system has permission to access only those resources it legitimately needs to perform its function. This means that such systems need very fine-grained access control measures.
The problem is challenging, as often configuration secrets are needed very early in the application lifecycle, and they themselves should protected by an encryption key. This creates a cyclical chicken and egg type problem of how to securely supply the secret to the application that protects the other secrets. The approach outlined is for an application running on AWS and is achieved by leveraging Amazon’s Simple Storage Service (S3), Key Management Service (KMS), and Identity Access Management (IAM) services.
Considerations
When deciding what approach to use for storing sensitive system configuration, there are several important considerations:
- How is read and write access to the configuration files controlled?
- How is the configuration updated?
- How does the architecture function across different environments?
The approach described in this article will aim to answer these questions while adhering to IAM security best practices.
Architecture
The architecture at a high level is to store the configuration in an S3 bucket encrypted under a KMS key. The application, running Amazon’s Elastic Cloud Compute (EC2) or AWS Lambda, will read the configuration from S3 on start-up. The application is assigned an IAM role which has a policy that grants read-only access to the bucket, and permission to decrypt using the KMS key. Lastly, a policy is placed on the bucket which restricts access to only specific allowed IAM roles.
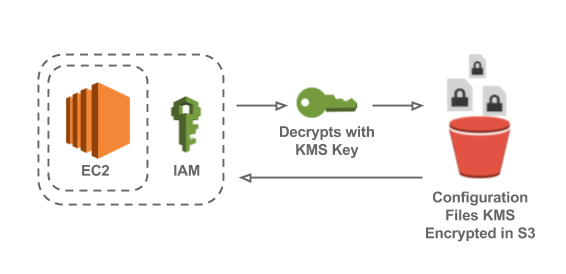
How KMS and IAM Solve the Chicken and Egg Problem
The configuration files need to be stored in an encrypted format and decrypted by the application. The primary challenge here is discerning how to securely pass the decryption key to the application. Attempting to protect this decryption key creates a cyclical problem; however, this issue is avoided utilizing KMS and IAM.

KMS is used to encrypt and decrypt the configuration files. When an application is running on EC2, it has an instance profile, which is used to associate an IAM role with the application. The instance profile causes AWS actions that are taken from the application's code (such as via the AWS Java SDK) to assume the IAM role's privileges. This role can be setup to have access to the KMS key which means when the application requests the configuration from S3, it can automatically decrypt the contents. Utilizing the instance profile and IAM permissions solves the awkward problem of having to securely supply a decryption key to the application.
IAM Setup
To obey the principle of least-privilege, there are three roles that must be created in IAM: A role which will be associated with the application’s EC2 instance; a role which will be used by developers to update the configuration; and a role which will be used by developers to read from the configuration. It is important that these three roles exist since neither a developer nor an application should have access to resources or actions outside of those they require to perform their task.
The need for the first two roles is self-evident, but the third is less obvious and is to be used under the very rare circumstances where a developer may need to read the configuration. It might be tempting to use the root AWS user to perform such a duty, but to adhere to IAM best practices this should be avoided. Using the root user for this purpose goes against the principle of least-privilege.
KMS Setup
Creating a KMS encryption key can be done through the IAM Management Console. It is possible to create the key with an external key material origin; however, this should only be done if required for the implementation. The key administrative permissions must be locked down to IAM users who will perform such actions and not granted to the EC2 instance role. The key usage permissions is where the three roles described in the IAM Setup section must be assigned. Below is a screenshot of the first step of creating a KMS key.
S3 Setup
Creating the S3 bucket can be done through the S3 Management Console. Once the bucket is created, a bucket policy must be added to limit access to the bucket. This is done via the bucket properties permissions section. The following is an example of working bucket policy for this architecture.
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "Statement 1: Ensure config is encrypted on upload"
"Effect": "Deny",
"Principal": "*",
"Action": "s3:PutObject",
"Resource": "arn:aws:s3:::CONFIG_BUCKET_NAME/*",
"Condition": {
"StringNotLike": {
"s3:x-amz-server-side-encryption-aws-kms-key-id": "KMS_KEY_RESOURCE_ARN"
}
}
},
{
"Sid": "Statement 2: Restrict role which writes configuration to only write actions.",
"Effect": "Deny",
"Principal": "*",
"NotAction": [
"s3:ListBucket",
"s3:PutObject",
"s3:PutObjectAcl",
"s3:PutObjectVersionAcl",
"s3:GetBucketLocation",
"s3:GetBucketVersioning"
],
"Resource": [
"arn:aws:s3:::CONFIG_BUCKET_NAME",
"arn:aws:s3:::CONFIG_BUCKET_NAME/*"
],
"Condition": {
"StringLike": {
"aws:userid": "ADMIN_WRITE_IAM_ROLE_ID:*"
}
}
},
{
"Sid": "Statement 3: Restrict roles which reads configuration to only read actions.",
"Effect": "Deny",
"Principal": "*",
"NotAction": [
"s3:ListBucket",
"s3:GetObject",
"s3:GetObjectAcl",
"s3:GetObjectVersionAcl",
"s3:GetBucketLocation"
],
"Resource": [
"arn:aws:s3:::CONFIG_BUCKET_NAME",
"arn:aws:s3:::CONFIG_BUCKET_NAME/*"
],
"Condition": {
"StringLike": {
"aws:userid": [
"APPLICATION_IAM_ROLE_ID:*",
"ADMIN_READ_IAM_ROLE_ID:*",
]
}
}
},
{
"Sid": "Statement 4: Deny anyone else",
"Effect": "Deny",
"Principal": "*",
"NotAction": [
"s3:GetBucketLocation",
"s3:GetBucketTagging"
],
"Resource": [
"arn:aws:s3:::CONFIG_BUCKET_NAME",
"arn:aws:s3:::CONFIG_BUCKET_NAME/*"
],
"Condition": {
"StringNotLike": {
"aws:userid": [
"APPLICATION_IAM_ROLE_ID:*",
"ADMIN_WRITE_IAM_ROLE_ID:*",
"ADMIN_READ_IAM_ROLE_ID:*",
"ROOT_ACCOUNT_ID"
]
}
}
}
]
}
The variables that must be replaced for this policy to work are the following:
CONFIG_BUCKET_NAMEKMS_KEY_RESOURCE_ARNADMIN_WRITE_IAM_ROLE_IDADMIN_READ_IAM_ROLE_IDAPPLICATION_IAM_ROLE_IDROOT_ACCOUNT_ID
The ids of the IAM roles can be retrieved using the AWS Command Line Interface via the following commands.
aws iam get-role --role-name TheNameOfTheRole
Dissecting the S3 Bucket Policy
The policy contains four statements.
- The first statement ensures that any files uploaded to the bucket are server-side-encrypted using the correct KMS key. This is really useful since it will ensure security standards are maintained.
- The second statement limits the role which will write to the bucket to only actions required for write operations.
- The third limits the roles which will read from the bucket to only actions required for read operations.
- The fourth and final statement restricts any other user or role from accessing the bucket. The reason
"NotAction":"s3:GetBucketLocation"is used rather than"Action":"s3:*", is that whenever a developer visits S3 in their browser, S3 in turn calls"S3:GetBucketLocation"on all buckets; this action results in an Access Denied message in CloudTrail, which can get noisy if the AWS account is configured to notify Access Denied and Authorization Failures for security purposes. See our recent article for a simple way to stay informed of activity in your AWS account.
A bonus of using S3 to store configuration files is that audit logging can trivially be enabled through the S3 bucket properties. Audit logging makes it easy to tell when files were accessed or updated and which user performed such actions, which assists greatly in a thorough Intrusion Detection System approach.
Fetching Configuration Files from the Application
The name of the S3 bucket should be stored in the non-sensitive application configuration. It is a good idea to fetch the credential files during application start-up to avoid incurring the cost of retrieving them from S3 every time they need to be accessed. Another motivation for fetching during start-up is as with any sensitive information, it is always preferable to minimize the number of times it is sent over any part of the network.
A straightforward approach is to store the files in a JSON format which makes them easy to parse. For example, the file stored in S3 could be called example_config.json with the following contents.
{
"secretKey":"abcdef-123456"
}
Within the application code, an object will exist which will be populated on load. To carry on with the example the corresponding object might look like this:
@Singleton
class ExampleConfig {
static String FILE_NAME_IN_S3 = “example_config.json”
String secretKey
}
The following Groovy snippet is an example of how an application config object could be populated using AWS’s S3 Java SDK.
ExampleConfig populateExampleConfig(String s3Bucket) {
ExampleConfig exampleConfig = ExampleConfig.getInstance()
AmazonS3Client client = new AmazonS3Client()
S3Object object = client.getObject(s3Bucket, exampleConfig.FILE_NAME_IN_S3)
def json = new JsonSlurper().parse(object.getObjectContent())
exampleConfig.secretKey = json.secretKey
return exampleConfig
}
The above example highlights the important fact that no AWS credentials need to be supplied to the application for it to be able to access the secure configuration in S3. When the applications calls S3 using as the AWS SDK, the applications 'Instance profile credentials' will be used since none were provided. Again, this is made possible by the IAM role associated with the EC2 instance. For more information on how the application receives its AWS credentials see Working with AWS Credentials.
A rather nice benefit of this architecture is that it is easy to add an endpoint to update and reload the configuration on the fly, without needing to restart the application. The endpoint can simply re-populate the applications config objects using the same method that is used during application startup.
Configuration Across Environments
It is crucial to use separate S3 buckets and KMS keys for at least production and nonproduction environments. It is also best practice to have different AWS accounts for different environments. Configuration will likely differ between environments so separating them allows production to be completely locked down, whilst granting the development team freedom to be more lenient on the other environments. This allows developers to move quickly without being constrained with inadequate permissions.
There are also likely differences in how a developer will run the application locally compared to the application running on EC2. For example, when a developer runs the application locally, suppose the AWS credentials used belong to an IAM user for that developer. The application running on their local machine will need to fetch the configuration files from the development S3 bucket. In this case, the IAM user could be given one of the roles described earlier which would allow them to read from the bucket.
Managing the AWS Infrastructure
The roles required for this architecture are only given permissions to perform their specific tasks. A question arises around how to manage this infrastructure. While trying to adhere to principle of least-privilege, the first cut would be to avoid using the root AWS user to manage such infrastructure. Instead, an IAM user should be created for these purposes which has permission to manage the IAM users, the KMS keys, and the S3 bucket policies. Since this user will have elevated permissions, it is a good practice to both restrict access to a physical FOB and have policies in place to be notified of suspicious activity.
Why This Architecture Is Well Suited for the Job
The motivation of this architecture is to enable fine-grained access control, adhering to the principle of least-privilege, with the goal of reducing the surface area of attack vectors. The approach outlined ensures that sensitive configuration files are stored in an encrypted format, and that only the IAM roles that need to read or update files are allowed to. Moreover, this approach also provides the additional benefits of S3 logging, enabling visibility into who is accessing such resources, as well as a secure infrastructure that ensures security measures are followed and stay up-to-date. Maintaining a secure system overall is an ongoing task, and the proper handling of sensitive configuration is a core component in an ever-evolving security landscape.




